Pingだけで満足?ネットワーク障害の切り分けでプロが絶対にしない事
目次[非表示]
1. 「Pingが通ればOK」は危険?プロがネットワーク障害で最初に行う思考法
ネットワーク障害が発生した際、多くの担当者が真っ先に「Ping」を打ちます。しかし、プロの現場では「Pingが通ったからネットワーク層(L3)までは正常だ」と短絡的に判断することはありません。Pingの応答はあくまで「ICMPプロトコルが通った」という事実に過ぎず、実際の業務アプリケーションが利用するTCPポートの疎通や、パケットの断続的な欠損(ドロップ)までを保証するものではないからです。
1-1. ネットワーク障害の「切り分け」とは“仮説検証”の繰り返しである
障害対応の本質は、あてずっぽうに設定変更を試すことではなく、論理的な「仮説検証」にあります。「特定のWebサイトだけが見られない」という事象に対し、「DNSの不具合ではないか?」「プロキシの設定ミスではないか?」といった仮説を立て、それを一つずつコマンドやログで証明していく作業です。このプロセスをスキップすると、原因とは無関係な場所をいじってしまい、事態をさらに悪化させるリスクがあります。
1-2. 情シス担当者が陥る「3つのNG行動」:勘・経験・再起動
中小企業の情シス担当者が陥りがちなのが「勘・経験・再起動」の3点セットです。「以前もこれで直ったから」という勘に頼り、根拠なくルーターを再起動させる行為は、障害の痕跡(ログ)を消し去るだけでなく、根本原因を闇に葬ることになります。再起動で一時的に復旧しても、数日後に再発すれば、それは「直った」のではなく「先送りした」に過ぎません。
1-3. ゴールは「復旧」ではなく「原因の特定と恒久対策」
ビジネスを止めないためには早期復旧が最優先ですが、真のゴールはその先の「恒久対策」です。
この考え方はネットワーク管理にも通じます。信頼性の高いネットワークを構築・維持するには、場当たり的な対応ではなく、障害の裏にある論理的な不備を見つけ出す「専門性」と、過去の事例を体系化する「経験」が不可欠です。原因を特定し、二度と同じトラブルを起こさない仕組みを作ることこそが、情シスとしての信頼(Trustworthiness)を築く鍵となります。
次は、この「論理的な切り分け」を支える世界標準のフレームワーク、OSI参照モデルについて解説します。
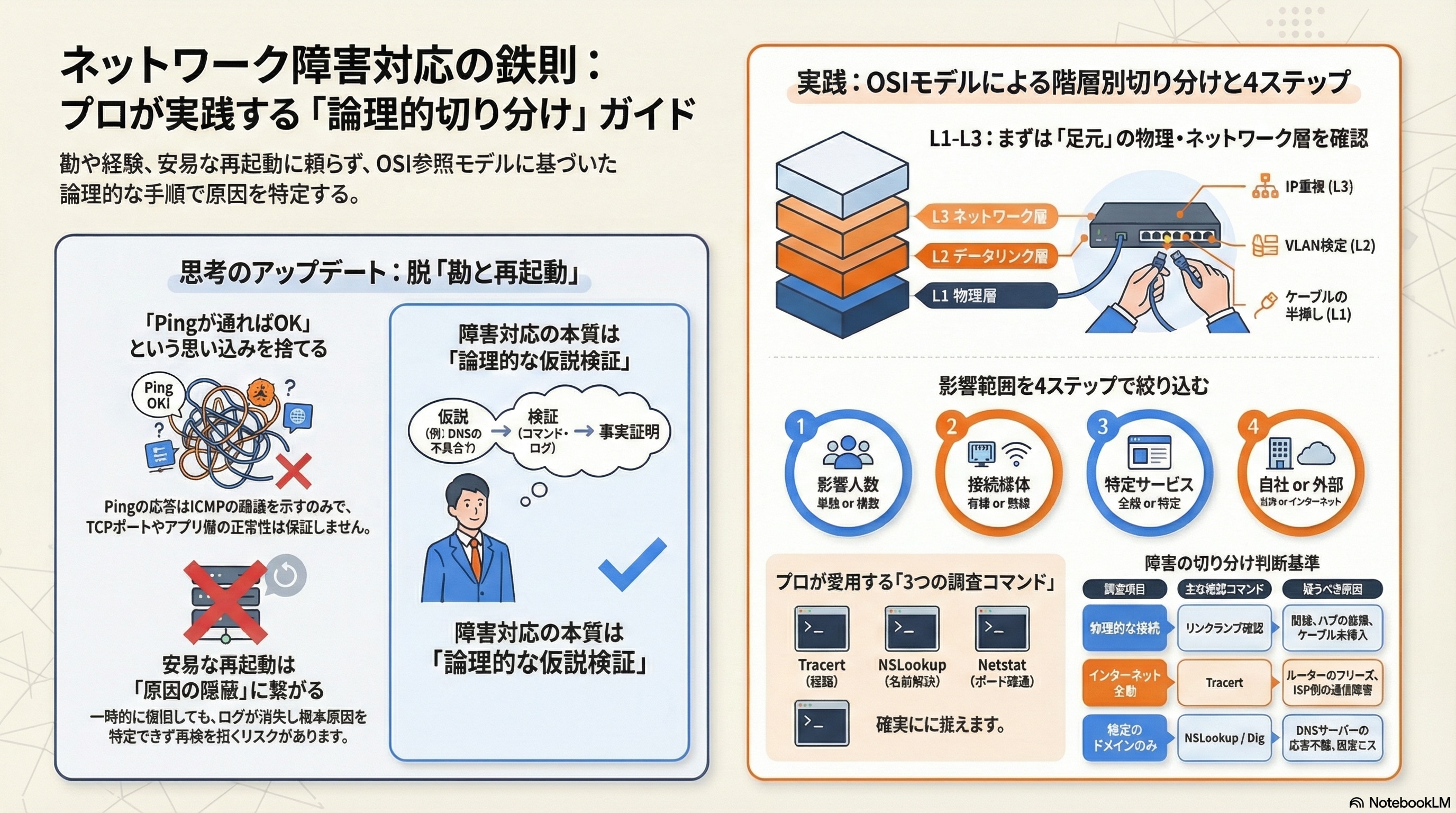
2. 【階層別】ネットワーク障害切り分けの鉄則「OSI参照モデル」の活用
ネットワークの構造を階層化した「OSI参照モデル」は、障害箇所の特定において最強の地図となります。下位層から順番に確認していくことで、上位層の複雑な設定に惑わされることなく、確実に原因を絞り込むことができます。
2-1. 【L1:物理層】まずは「線」と「光」を疑う(LANケーブル・リンクアップ)
最も基本的でありながら見落とされやすいのが「物理層」です。LANケーブルの半挿し、断線、あるいはスイッチングハブのポート故障などがこれに該当します。
プロはまず「リンクランプ(Link Up)」が点灯しているかを確認します。また、ケーブルの規格(Cat5eやCat6など)が通信速度に見合っているか、物理的なノイズ干渉がないかもチェック対象です。
2-2. 【L2:データリンク層】MACアドレス学習とVLANの落とし穴
物理層に問題がなければ、次は「データリンク層」です。ここではMACアドレスを元にした通信が行われます。
中小企業のオフィスで多いのが、VLAN設定ミスによる通信途絶です。ハブを交換した際にVLAN IDの設定を忘れたり、タグVLANの受け渡し設定(トランクポート)を間違えたりすると、物理的には繋がっていてもデータは届きません。
2-3. 【L3:ネットワーク層】IPアドレス重複とルーティングの不整合
「ネットワーク層」ではIPアドレスが主役になります。ここで頻出するのが「IPアドレスのバッティング(重複)」です。
固定IPを割り当てたサーバーと、DHCPで払い出されたPCのIPが重複すると、通信が極めて不安定になります。また、デフォルトゲートウェイの設定ミスや、スタティックルート(静的経路)の矛盾により、パケットが迷子になるケースも多々あります。
2-4. 【L4-L7:上位層】ポート開放・DNS・プロキシ・証明書の壁
IP通信自体は正常でも、アプリケーションが動かない場合は「上位層」を疑います。
ファイアウォールによる特定のポート(HTTPSの443番など)の遮断、DNSサーバーの応答遅延、さらにはSSL証明書の期限切れなどが代表例です。
「ブラウザでGoogleは見られるのに、自社基幹システムだけエラーが出る」といった場合は、この層に原因が潜んでいる可能性が高いでしょう。
階層ごとの特性を理解したところで、次はこれらの仮説を実際に検証するためのツール(コマンド)の使い方を見ていきましょう。
3. 【実践】プロが駆使するネットワーク調査コマンド5選と「読み解き方」
ネットワーク障害の現場でプロが使うツールは、OS標準のコマンドが中心です。派手なツールは不要ですが、出力結果から「何が読み取れるか」の洞察力が問われます。
3-1. Ping:応答速度の「揺らぎ(Jitter)」と「パケットロス」を見逃さない
Pingは宛先との疎通を確認する基本中の基本です。しかし、プロは「Reply from...」という文字だけでなく、その「数値」を凝視します。
特に「time=1ms」が突然「500ms」になるような「揺らぎ(ジッター)」や、数回に一度発生する「Request timed out(パケットロス)」は、無線LANの干渉やネットワーク経路の輻輳(渋滞)を示唆する重要なサインです。
3-2. Tracert (Traceroute):経路のどこで「タイムアウト」しているか
宛先に届かない場合、その「途中」のどこで止まっているかを突き止めるのがTracertです。
パケットがバケツリレーのようにルーターを通過する様子を表示し、応答が途絶えたポイントが原因箇所となります。
3-2-1. 社内ルーターで止まる場合 vs ISP以降で止まる場合の判断
1番目のホップ(自分のデフォルトゲートウェイ)で止まるなら自社PCやLANの問題です。社内ルーターまでは通るが、その先で止まる場合は、ルーター設定やプロバイダ(ISP)側の障害が疑われます。この一歩踏み込んだ判断が、ベンダーへの迅速な依頼に繋がります。
3-3. NSLookup / Dig:名前解決トラブルかネットワークダウンかの判別
「IPアドレスを直接打てばサイトが開くのに、ドメイン名(URL)では開かない」――これは典型的なDNSトラブルです。
NSLookupを使い、ドメイン名からIPアドレスが正しく引けるかを確認します。もし応答がなければ、ネットワーク全体ではなくDNSサーバーの設定や死活を疑うべきです。
3-4. Ipconfig / Getmac:自身のPC環境が「正常」である証明
自分の足元を固めることも重要です。「ipconfig /all」を叩き、DHCPから適切なIPが割り当てられているか、DNSサーバーのアドレスは正しいかを再確認します。
もしIPが「169.254.x.x」になっていれば、DHCPサーバーから情報を取得できておらず、LAN内の問題であることが確定します。
3-5. Netstat / Powershell (Test-NetConnection):特定のポートが叩けるかの確認
Pingは通るがサービスが使えない時、ポートレベルの疎通を確認します。
最近のWindowsであれば、PowerShellの「Test-NetConnection -ComputerName [宛先] -Port [番号]」が便利です。これでTCPコネクションが確立できるかを確認し、失敗するならファイアウォールでの遮断を疑います。
これらの武器を使いこなすために、実際の切り分け手順をフローチャート化して整理しておきましょう。
4. 現場で役立つ「障害切り分けフローチャート」完全版
場当たり的な対応を防ぐため、以下の4ステップで影響範囲を絞り込んでいくのがプロの鉄則です。
4-1. ステップ1:影響範囲の特定(一箇所か、全体か)
まずは「誰が困っているか」を確認します。
- 特定の1名のみ:そのPC、LANケーブル、ハブのポートが原因。
- 部署単位(1つの島):その部署を収容しているフロアスイッチが原因。
- 会社全体:コアスイッチ、ルーター、あるいは外部回線が原因。
この切り分けだけで、調査対象を9割削減できます。
4-2. ステップ2:有線・無線の切り分け(媒体の問題か、経路の問題か)
無線LANで繋がらない場合、有線LANに繋ぎ替えてみます。
有線で繋がるなら、アクセスポイントの故障や電波干渉、認証不備の問題です。どちらもダメなら、さらに上位のネットワーク機器や回線自体の問題を疑います。
4-3. ステップ3:特定サービスのみか、インターネット全般か
「Yahoo!は見られるが社内システムがダメ」なのか、「全てのサイトが見られない」のかを判別します。
特定サイトのみなら、そのサーバーのダウンや経路制限(ファイアウォール)が疑われます。全てダメなら、ルーターのフリーズやISPの通信障害の可能性が高まります。
4-4. ステップ4:自社設備(ルーター・HUB)か、外部(ISP・クラウド)か
自社のルーターまでPingが飛ぶかを確認します。
自社ルーターが正常なら、そこから先の「ONU(回線終端装置)」や「ISPの網内」で問題が起きている可能性があります。この段階で、契約している通信会社に問い合わせる根拠が揃います。
切り分けが済んだら、次は「なぜそうなったのか」の意外な落とし穴をチェックしていきましょう。
5. なぜか見落とされる「ネットワーク障害」の意外な原因ワースト5
論理的に追い詰めても原因が見つからない時、現場では「物理的なヒューマンエラー」や「設定の盲点」が牙を剥きます。
5-1. ループ接続:1本のLANケーブルがオフィスを沈黙させる
最も恐ろしいのが「ネットワークループ」です。1本のLANケーブルの両端を同じスイッチに挿してしまうことで、データが無限に回り続け、帯域を食い潰します。
これが発生すると、ネットワーク全体が「沈黙」し、どのコマンドも応答しなくなります。ループ検知機能のない安価なハブを使っている中小企業では、掃除や席替えの際に頻発します。
5-2. IPアドレスのバッティング:野良ルーターや固定IPの重複
社員が勝手に自宅から持ってきた無線ルーターを繋ぐ、いわゆる「野良ルーター」がDHCPサーバーとして動作し、社内に誤ったIPを配り始めるケースがあります。
これにより、一部のPCがインターネットに出られなくなる、あるいは特定のサーバーとIPが重複してサーバーがダウンするといった被害が発生します。
5-3. DNSサーバーの障害:ネットワークは生きていても「住所不明」
意外と多いのが、ISPから指定されたDNSサーバーが攻撃を受けていたり、メンテナンス中だったりする場合です。
IPでの通信(Ping 8.8.8.8など)ができるのにブラウザが動かない時は、Googleが提供するパブリックDNS(8.8.8.8)に一時的に切り替えてみることで、DNS起因であることを即座に判断できます。
5-4. ファイアウォール・ウイルス対策ソフトの「勝手な遮断」
OSのアップデートや、ウイルス対策ソフトのシグネチャ更新により、昨日まで通っていた通信が「脅威」とみなされ遮断されることがあります。
特にWindows Defenderやノートンなどの個人向けソフトが混在している環境では、特定の端末だけが通信不可になる原因の筆頭です。
5-5. MTUサイズの問題:VPN経由で「特定のサイトだけ開かない」
「文字だけのサイトは開くが、画像が多いサイトや大きなファイルの送受信だけ失敗する」というマニアックな障害があります。
これはVPN通信時に付加されるヘッダーのせいで、パケットサイズが通信可能範囲(MTU)を超えてしまい、破棄されることが原因です(フラグメンテーションの失敗)。VPNを多用するリモートワーク環境下では注意が必要です。
こうした複雑な原因を自力で特定できない場合、外部の力を借りることになります。その際の「伝え方」で復旧スピードは大きく変わります。
6. 情シスがベンダーやISPに「最短で動いてもらう」ための報告術
「インターネットが繋がらないので見てほしい」という報告は、プロへの依頼としては不十分です。有能な情シスは、ベンダーが現場に来る前に「ほぼ原因の特定が終わっている」レベルの情報を渡します。
6-1. 必須情報を揃える:発生時刻・端末・IP・実施したコマンド結果
報告の際は、最低限以下のデータをテキスト化して送ります。
- 発生日時:何時何分から発生したか(ログとの照合用)。
- 影響端末:特定のPC名、IPアドレス。
- コマンド出力:PingやTracertの結果をコピー&ペースト。
これにより、サポート担当者は「物理層はクリアしているな」と判断でき、電話一本で解決に導けることもあります。
6-2. 5W1Hで伝える「障害状況報告シート」の作り方
報告を構造化しましょう。
- Who(誰が):営業部の5名。
- When(いつ):本日午前9時の始業直後から。
- What(何が):社内ファイルサーバーへのアクセスができない。
- Where(どこで):3Fオフィス内。
- Why(なぜ):1Fのスイッチ故障か、VLANの設定ミスを疑っている。
- How(どのように):Pingは通るが、ポート445の疎通がタイムアウトする。
6-3. エスカレーション先(ISP、保守ベンダー、ビル管理)の優先順位
原因の所在に応じて、問い合わせ先を峻別します。
- 社内設備(ハブ・LAN):保守ベンダーへ。
- 外部回線(ONUより先):ISP・キャリアへ。
- 電源・設備(ブレーカー落ち):ビル管理会社へ。
切り分けが正しければ、無駄な「たらい回し」を回避し、最短での復旧が可能です。
最後は、こうした障害対応に追われないための「攻めの情シス」の準備についてです。
7. 障害を「未然に防ぐ」ために中小企業の情シスが今すぐできる事
障害対応は「起きてから」ではなく「起きる前」に勝負が決まっています。予算の限られた中小企業でも、以下の3点は明日から実行可能です。
7-1. ネットワーク構成図の最新化(「現場の継ぎ足し」を視覚化する)
「どこにどのハブがあるか分からない」状態が、障害対応を長引かせる最大の原因です。
継ぎ足しで増えたハブ、天井裏のアクセスポイント、これらを1枚の図面にまとめましょう。図面があるだけで、障害時に「あそこのスイッチが怪しい」と即座に目星がつくようになります。
7-2. 死活監視ツールの導入(無料ツールから始める監視体制)
ネットワーク管理にも、常に状態を「評価」する仕組みが必要です。
ZabbixやNagiosといった高機能なツールでなくても、無料の「Ping監視ツール」をサーバーに常駐させるだけで十分です。障害が起きる前に「最近応答が遅い」「パケットロスが1%出ている」といった予兆を捉えることができます。
7-3. 定期的なファームウェア更新とバックアップの重要性
ルーターのフリーズは、多くの場合ファームウェアのバグです。定期的な更新で脆弱性と安定性を確保しましょう。
また、ルーターやスイッチの設定ファイル(Config)のバックアップは必須です。万が一機器が物理的に故障しても、設定の控えがあれば、新しい機器に流し込むだけで数分で復旧できます。
8. まとめ:ネットワーク障害の切り分けは「論理」と「準備」が9割
ネットワーク障害は、情シス担当者にとって最大の試練ですが、同時に「専門性」を発揮する最大のチャンスでもあります。
- Pingだけで判断せず、OSI参照モデルに基づき下位層から論理的に切り分ける。
- 「勘」に頼った再起動ではなく、コマンドで事実を積み上げ、仮説を検証する。
- 影響範囲と原因箇所を特定し、ベンダーへ構造化された報告を行う。
- 構成図の作成や死活監視など、未然に防ぐ「準備」を怠らない。
ネットワークの安定は、企業の生産性に直結します。本記事で紹介した思考法と手順を身につけることで、突発的な障害にも慌てず、プロとして迅速かつ確実な対応を実現してください。