NOCとは「監視」ではない?安定稼働が生む情シスの“本当の価値”
目次[非表示]
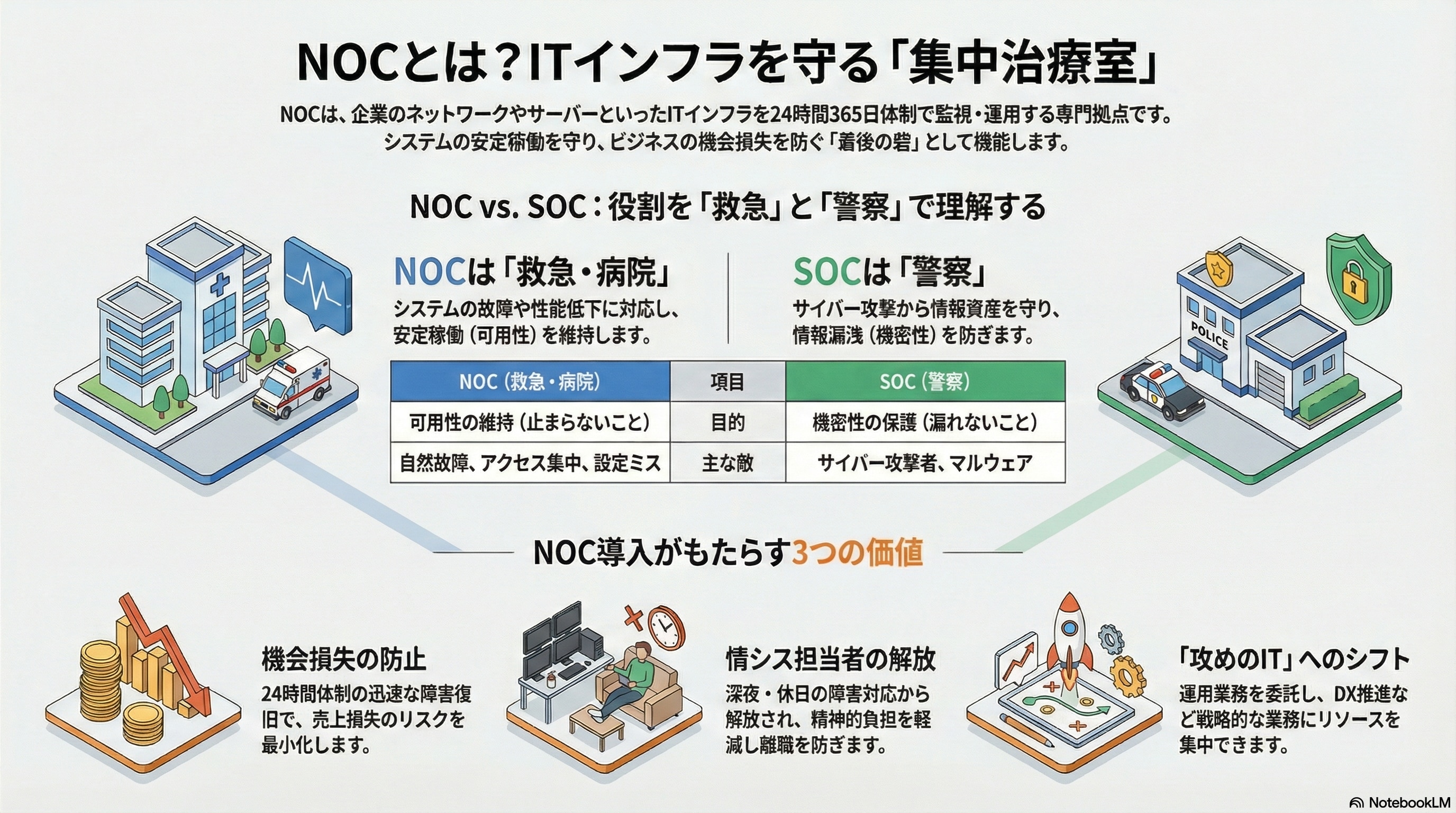
NOC(Network Operations Center)とは?一言でいうと「心臓を守る集中治療室」
企業活動の生命線であるネットワークやサーバー。これらが24時間365日、止まることなく動き続けるように監視・運用する専門拠点がNOC(Network Operations Center)です。
人間で例えるならば、企業のITインフラは「心臓」であり、NOCはその鼓動を片時も離さずモニターし、異常があれば即座に処置を行う「集中治療室(ICU)」に相当します。情報システム担当者(情シス)にとって、NOCは単なる監視室ではなく、夜間や休日の平穏を守り、ビジネスの機会損失を防ぐための「最後の砦」と言えるでしょう。
NOCの読み方と定義:24時間365日、ネットワークを見守る「砦」
NOC(ノック)とは、ネットワーク機器、サーバー、クラウドサービスなどの稼働状況を専門の技術者が常駐(またはリモート監視)して管理する組織や施設のことです。
主な役割は以下の3点に集約されます。
- 可用性の維持:システムが止まらない状態を維持する。
- 性能管理:遅延やパケットロスなどのパフォーマンス低下を防ぐ。
- 障害対応:トラブル発生時に検知・切り分け・復旧を行う。
NOC(Network Operation Center)とは、主にネットワークの性能や可用性を監視・管理する組織です。
NOCとSOCの違い:役割分担を「警察」と「救急」で理解する
「NOC」とよく混同されるのが「SOC(Security Operations Center:ソック)」です。どちらも24時間体制で監視を行いますが、その目的と戦う相手が明確に異なります。
- NOC(救急・病院):
- 敵:自然故障、アクセス集中、設定ミス、経年劣化。
- 目的:「可用性」の維持(止まらないこと、遅くないこと)。
- アクション:健康診断(監視)、応急処置(再起動)、治療(修理)。
- SOC(警察):
- 敵:サイバー攻撃者、マルウェア、内部不正。
- 目的:「機密性」の保護(漏れないこと、改ざんされないこと)。
- アクション:パトロール(ログ分析)、犯人検挙(攻撃遮断)、現場検証(フォレンジック)。
近年はサイバー攻撃が原因でシステム障害(可用性の欠如)が起きるケースも増えており、NOCとSOCの連携は不可欠ですが、専門とするスキルセットは別物です。「泥棒が入った(セキュリティインシデント)」のに「医者(NOC)」を呼んでも解決しないように、それぞれの役割を正しく理解する必要があります。
なぜ今、中小企業でNOCが注目されているのか?
かつてNOCは、通信キャリアや大規模データセンターだけが持つ設備でした。しかし現在、多くの中小企業が外部のNOCサービスを利用し始めています。その背景には3つの要因があります。
- 「ひとり情シス」の限界:クラウド化で監視対象が激増し、少人数の担当者では24時間の有人監視が物理的に不可能になった。
- ダウンタイムコストの増大:WebサービスやECに依存する企業が増え、1時間のシステム停止が致命的な売上損失に直結するようになった。
- AIによる運用の高度化:2026年に向けてAIエージェントによる自動復旧が進み、中小企業でも安価に高度な監視が可能になりつつある。
NOCの具体的な業務フロー:障害発生時、現場では何が起きている?
NOCサービスの利用時、実際にアラートが鳴ってから解決するまで、裏側ではどのような動きが行われているのでしょうか。一般的な業務フローを解説します。
1. 監視・検知(Monitoring):予兆を見逃さない
監視ツール(Zabbix、Datadog、Mackerelなど)やAI監視システムを用い、対象機器を常時モニタリングします。
単に「止まった(死活監視)」ことの検知だけでなく、「CPU使用率が急上昇している(しきい値監視)」や「いつもと違う挙動をしている(アノマリー検知)」といった予兆を捉えることが重要です。
2. 一次切り分け(Triage):その障害は「誰」の責任か?
アラートを検知したNOCエンジニアは、その障害が「どこ」で起きているかを特定(切り分け)します。
- ハードウェア故障か?(サーバー本体、ルーター)
- 回線の問題か?(キャリア網、ISP)
- アプリのバグか?(Webサーバー、DB)
- クラウド側の障害か?(AWS、Azure自体の障害)
この「切り分け」こそが情シスにとって最も手間がかかる部分であり、NOCの腕の見せ所です。誤検知(オオカミ少年)を排除し、本当に対応が必要な事象だけをフィルタリングします。
3. 復旧措置・エスカレーション(Remediation):夜中の電話対応からの解放
事前に定めた手順書(ランブック)に基づき、NOCエンジニアが復旧作業を行います。
- レベル1(自動/定型対応):プロセスの再起動、サーバーの再起動、キャッシュのクリアなど。これらは情シスへの連絡なしに即時実行されることが多く、担当者は「寝ている間に直っていた」状態になります。
- レベル2(エスカレーション):物理的な故障対応や、判断が必要な重大インシデントの場合、ベンダーや情シス担当者へ緊急連絡を行います。
4. レポーティング・改善提案:再発防止への道筋
月次などで監視レポートが提出されます。「先月は〇回アラートがあり、〇件を自動復旧しました」という報告に加え、「このサーバーはリソースが逼迫傾向にあるため、来月増強が必要です」といったキャパシティプランニングの提案も行われます。
NOC導入の3大メリット:安定稼働が生む情シスの“本当の価値”
メリット1:圧倒的な「可用性」の担保と機会損失の防止
最大のメリットは、ビジネスを止めないことです。
例えば、ECサイト運営企業で夜中の2時にサーバーがダウンした場合、翌朝9時の出社まで気づかなければ7時間分の売上を失います。NOCがあれば、数分以内に検知し、15分後には復旧(または暫定対応)が完了している可能性があります。
メリット2:情シス担当者の「メンタルヘルス」と「リソース」の解放
多くの中小企業情シスが抱える悩みが、「いつ電話が鳴るかわからない」という精神的プレッシャーです。
休日や深夜のデート中、家族団らんの時間に緊急のアラートメールに怯える必要がなくなります。この「安心感」は、離職防止やモチベーション維持に直結します。
メリット3:「攻めのIT」へのシフトチェンジ(DX推進)
日々のログ確認や障害対応といった「守り」の業務をNOCにアウトソースすることで、情シスは本来やるべき「攻め」の業務に時間を割けるようになります。
- 基幹システムのクラウド移行計画
- 生成AIを活用した業務効率化の推進
- セキュリティポリシーの策定(ゼロトラスト対応など)
これらはまとまった思考時間を必要とするため、割り込みタスクが多い運用業務から離れることが成功の鍵となります。
「自社構築」vs「アウトソーシング」どちらが正解?コストとリスクの比較
NOC機能を持つには、「自社でチームを作る(オンプレミスNOC)」か「外部サービスを利用する(NOCアウトソーシング)」かの2択があります。結論から言えば、中小企業においてはアウトソーシングが圧倒的に合理的です。
自社でNOCを構築する場合のハードル(オンプレミスNOC)
24時間365日の有人監視を自社で実現しようとすると、莫大なコストとリスクが発生します。
- 人件費:24時間体制を組むには、最低でも4〜5人のシフト勤務が必要です。人件費だけで年間2,000〜3,000万円以上かかります。
- 採用・教育:ネットワークスキルを持つエンジニアを5名採用し、維持し続けるのは至難の業です。
- 設備投資:監視ルーム、冗長化電源、大型モニターなどのファシリティ費用がかかります。
アウトソーシング(NOCサービス)を利用する場合の費用対効果
一方、NOCサービスを利用すれば、設備と人材をシェアすることで低コストで利用できます。
- コストイメージ:監視対象のデバイス数による従量課金が一般的です。
- デバイス単価:数百円〜数千円/月
- 初期費用:数万円〜
- 月額トータル:数万円〜数十万円(規模による)
ネットワーク監視 ネットワーク装置のパフォーマンスやトラフィックをICMPやSNMPで監視 単価目安: ¥250/デバイス/月
出典: Site24x7「プランと価格」
結論:従業員規模別・おすすめの運用スタイル
- 〜50名(ひとり情シス):SaaS型の自動監視ツール+平日日中のみ自社対応、夜間は「通知のみ」または安価な監視代行。
- 50〜300名(情シス2-3名):NOCアウトソーシング推奨ゾーン。コア業務への集中が必要な時期。
- 300名〜(情シスチームあり):一部ハイブリッド。重要な基幹系は自社で見つつ、定常監視はアウトソース。
失敗しないNOCサービスの選び方・7つのチェックリスト
NOCサービスは「どこも同じ」ではありません。安さだけで選ぶと、「通知メールが転送されてくるだけ(自分たちが起きる必要がある)」という事態になりかねません。
1. 監視範囲とレイヤー(どこまで見てくれるか?)
死活監視(Ping)だけでなく、ポート監視、リソース監視(CPU/メモリ)、さらにURL監視やシナリオ監視(ログインできるか?)まで対応しているか確認しましょう。
2. 障害対応の深さ(「通知だけ」か「復旧」か?)
これが最も重要です。「アラートをメールで知らせるだけ」のサービスは安価ですが、情シスの負担は減りません。「手順書に基づく再起動」や「ベンダーへの電話連絡代行」まで行ってくれるかを確認してください。
3. SLA(サービス品質保証)の内容
「障害検知から〇分以内に通知する」「稼働率99.9%を保証する」といったSLAが設定されているか。明確な基準がないサービスは、品質がオペレーターの個人技に依存するリスクがあります。
4. SOCとの連携体制
セキュリティインシデントが疑われる場合、スムーズにSOC(またはセキュリティ担当)へ連携できるフローがあるか。近年は「NOC/SOC統合サービス」も増えています。
5. 柔軟性とカスタマイズ性
「Aサーバーは即時電話してほしいが、Bサーバーは翌朝メールでいい」といった、柔軟な通知ルールの設定が可能か。
6. レポートの品質と定例会の有無
機械的なログ出力だけでなく、傾向分析や改善提案が含まれているか。月1回の定例会で顔を合わせて報告してくれるベンダーは信頼できます。
7. コスト体系(デバイス課金 vs トラフィック課金)
中小企業の場合、「デバイス課金(監視対象数)」が予測しやすくおすすめです。クラウド利用が多い場合は、トラフィック量で課金されるとコストが跳ね上がる可能性があるため注意が必要です。
よくある質問(FAQ):NOC導入の不安を解消
Q. 小規模なオフィスでもNOCは必要ですか?
従業員数が少なくても、「ネットが止まったら業務が止まる」業態であれば必要です。特にリモートワーク主体の企業では、VPNやクラウドへの接続監視が生命線となります。
Q. セキュリティ監視(SOC)と兼任はできませんか?
小規模であれば「統合監視サービス」として兼任されるケースもありますが、専門性は異なります。まずは「止まらないこと」を最優先するならNOC、情報漏洩対策を優先するならSOC、あるいはその両方をカバーするマネージドサービス(MSP)を選定しましょう。
Q. 既存の監視ツール(Zabbix等)はどうなりますか?
多くのNOCサービスは、既存の監視環境(Zabbixなど)のアラートを受け取って対応する運用が可能です。無理にツールを入れ替える必要がない場合も多いため、ベンダーに相談してみましょう。
まとめ:NOC導入は「情シスの働き方改革」の第一歩
NOCの導入は、単なるアウトソーシングではなく、情報システム部門の「働き方改革」そのものです。
- NOCは単なる監視室ではなく、安定稼働を守る「砦」である。
- SOCとは役割が異なり、可用性の維持に特化している。
- アウトソーシング活用により、情シスは泥臭い障害対応から解放され、コア業務に集中できる。
- 選定時は「通知」だけでなく「復旧・ベンダー対応」まで任せられるかを確認する。
2026年にはAIによる自動化がさらに進み、NOCは「障害を直す」場所から「障害を予知して回避する」場所へと進化していくでしょう。まずは自社の現状のリスクを洗い出し、夜も安心して眠れる体制づくりを始めませんか。
今の監視体制に限界を感じていませんか?
自社に最適な監視レベルはどこか、まずは現状のコストとリスクを可視化してみましょう。